PDFの構造
PDF内における画像の格納方法
PDFファイルでは、画像は通常、別個のオブジェクト(XObject)として格納され、これには画像の生バイナリデータが含まれます。これらの画像オブジェクトは、ページやファイルのリソースオブジェクトにリストされ、それぞれ固有の名前(例: Im1)が付けられています。PDFに埋め込まれた画像をTifやGif、Bmp、Jpeg、Pngなどと同一視するのは誤りです。
実際には、これらはピクセルのバイナリデータと、画像の色空間やその他の情報を含むものです。PDFの生成時には、画像が分割され、PDF作成ツールによって異なる方法で保存されることがあります。
以下に示すのは、AcrobatのPDFオブジェクトビューアでの表示例です。
AcrobatのPDFオブジェクトビューア
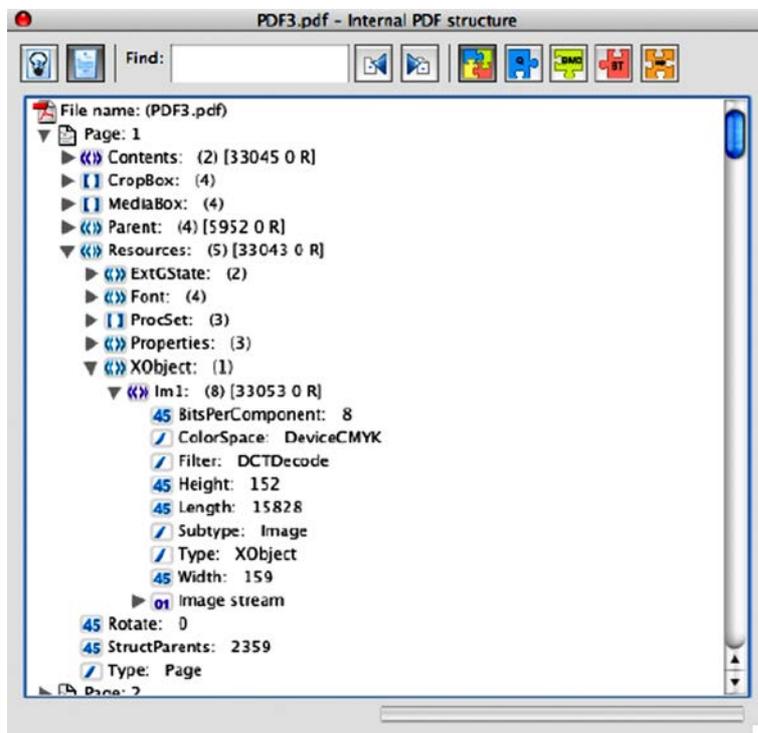
生の画像データは、ページの必要なサイズに合わせて調整されることがありますが、そうでない場合もあります。その場合、画像は描画時に拡大または縮小されます。PDFファイルの生成方法は、使用されるPDF作成ツールによって大きく変わります。
実際の画像データは圧縮が可能で、使用される圧縮形式の一つにDCTDecodeがあります。これはJPEGで用いられる圧縮方式と同じです(JPXはJpeg2000に相当します)。このデータを抽出すると、JPEGファイルとして開くことが可能ですが、色空間データを適切に調整する必要が生じる場合があります。
この画像は、PDFコンテンツストリーム内でDOコマンドと画像名(例: Im1)を用いて描画されます。同じ画像は何度も使用されることがあり、DOコマンドを実行する際に設定される値によって拡大・縮小、回転、切り抜きなどが行われます。一見すると単一の画像のように見えるものも、実際には複数の画像で構成されているか、または画像でないこともあり得ます。
つまり、PDFから画像を抽出したい場合、提供されているすべての生データから画像を再構築する作業が必要になります。また、画像の「RAW」バージョン(より高解像度で、元のサイズを保持している場合もある)と、画像の切り抜きや拡大縮小されたバージョンの両方が存在し、これらはどちらも抽出が可能です。